In this two part series we are going to take Burp Suite Project files as input from the command line, parse them, and then feed them into a testing pipeline.
The series is broken down into two parts:
- Getting at the Data (i.e. from the CLI to feeding the pipeline)
- 8 Bug Hunting Examples with burpsuite-project-parser (i.e. from the pipeline to testing)
Introduction
Two years ago I pushed to Github a Burp Suite plugin with a mouthful of a name: burpsuite-project-parser. It started out to solve a very simple problem.
I am on day 10 of a web application assessment, I intercept a request, and I ask myself “Where the $@#* have I seen that parameter before?!?!”
When I am on a long assessment or bug hunting over a period of time I keep multiple sequential Burp project files (e.g. 06-01-2022.burp, 06-08-2022.burp, etc). Typically I would need to open and close Burp Suite for each project file using the search UI to hunt for this single parameter or URI. This led to the idea:
This was the first problem solved by burpsuite-project-parser. From the CLI it will output every request/response (or findings) from a project file. For example:
...
{"request":{"url":"http://secret.targethost.com:80/success.txt","headers":["Host: secret.targethost.com","User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:80.0) Gecko/20100101 Firefox/80.0","Accept: */*","Accept-Language: en-US,en;q\u003d0.5","Accept-Encoding: gzip, deflate","Cache-Control: no-cache","Pragma: no-cache","Connection: close"],"uri":"/success.txt","method":"GET","httpVersion":"HTTP/1.1","body":""},"response":{"url":"http://secret.targethost.com:80/success.txt","headers":["Content-Type: text/plain","Content-Length: 8","Last-Modified: Mon, 15 May 2017 18:04:40 GMT","ETag: \"ae780585fe1444eb7d28906123\"","Accept-Ranges: bytes","Server: AmazonS3","X-Amz-Cf-Pop: ORD53-","X-Amz-Cf-Id: ADZK","Cache-Control: no-cache, no-store, must-revalidate","Date: Mon, 14 Sep 2020 17:59:54 GMT","Connection: close"],"code":"200","body":"success\n"}}
{"request":{"url":"https://mail.targethost.com:443/somepage","headers":["Host: x.tesla.com:443/somepage","User-Agent: ...
...The Github page for burpsuite-project-parser has the most up to date installation instructions so I won't repeat those here. Instead I want to talk about how to parse larger amounts of Burp data in our pipeline.
Moving Faster with Burp Suite User-Level Configuration

You may or may not have played with Burp User-Level Configurations; they were certainly new to me when I started this project. The Burp Suite documentation does the best job of describing what's included so I will just screenshot it here:

The most important point is that we can create a User-Level configuration to include just the burpsuite-project-parser Extender tool and not break our default Burp Suite configuration. This allows the loading and unloading of Burp Suite to be much faster as we are only applying one extension against the project file.
The following assumes you have already installed Burp Suite Project File Parser; if not, install it before going forward.
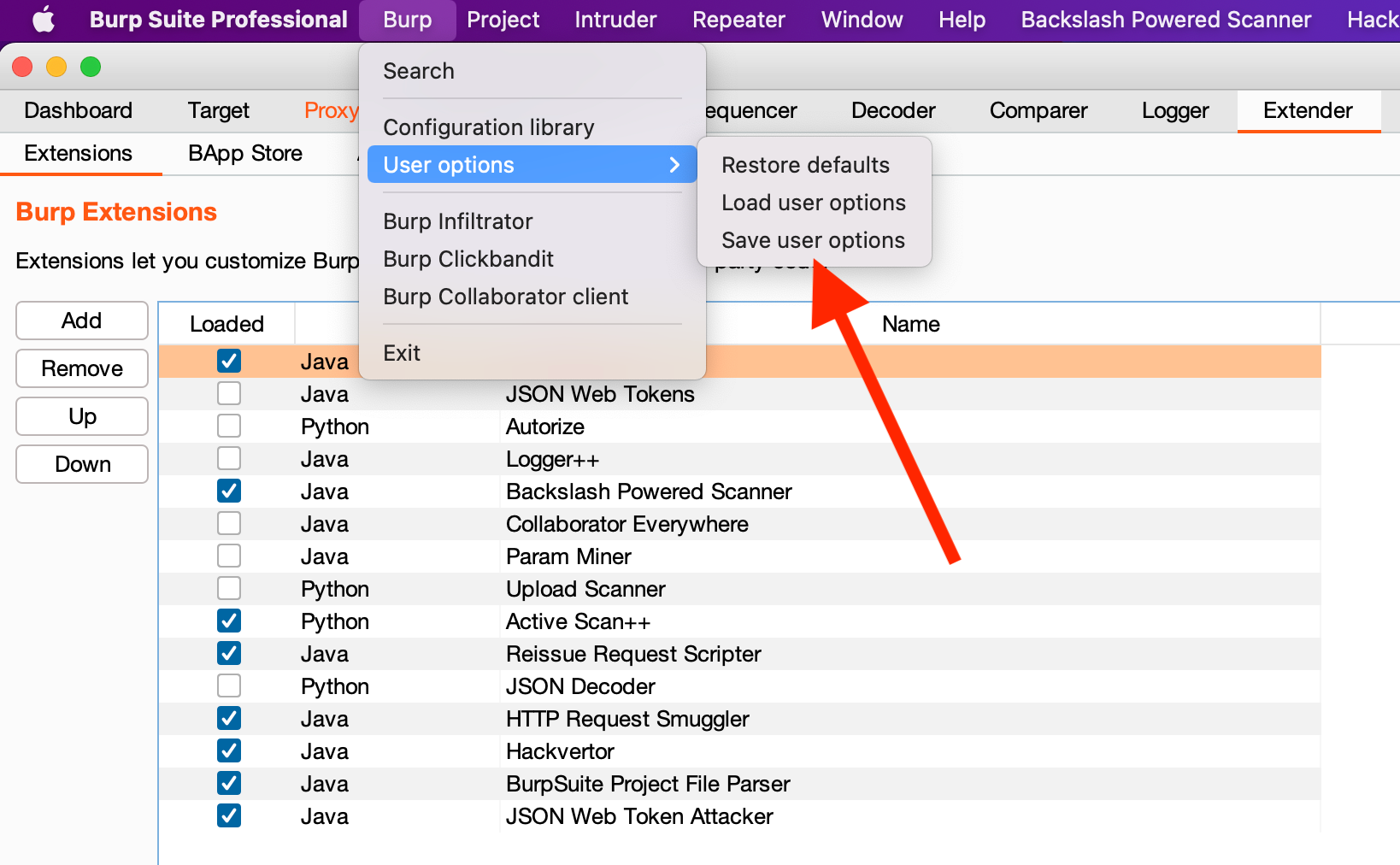
First, save your existing user options; Burp > User Options > Save user options. Use a memorable name such as "DEFAULT_BURP_USER_OPTIONS.json":
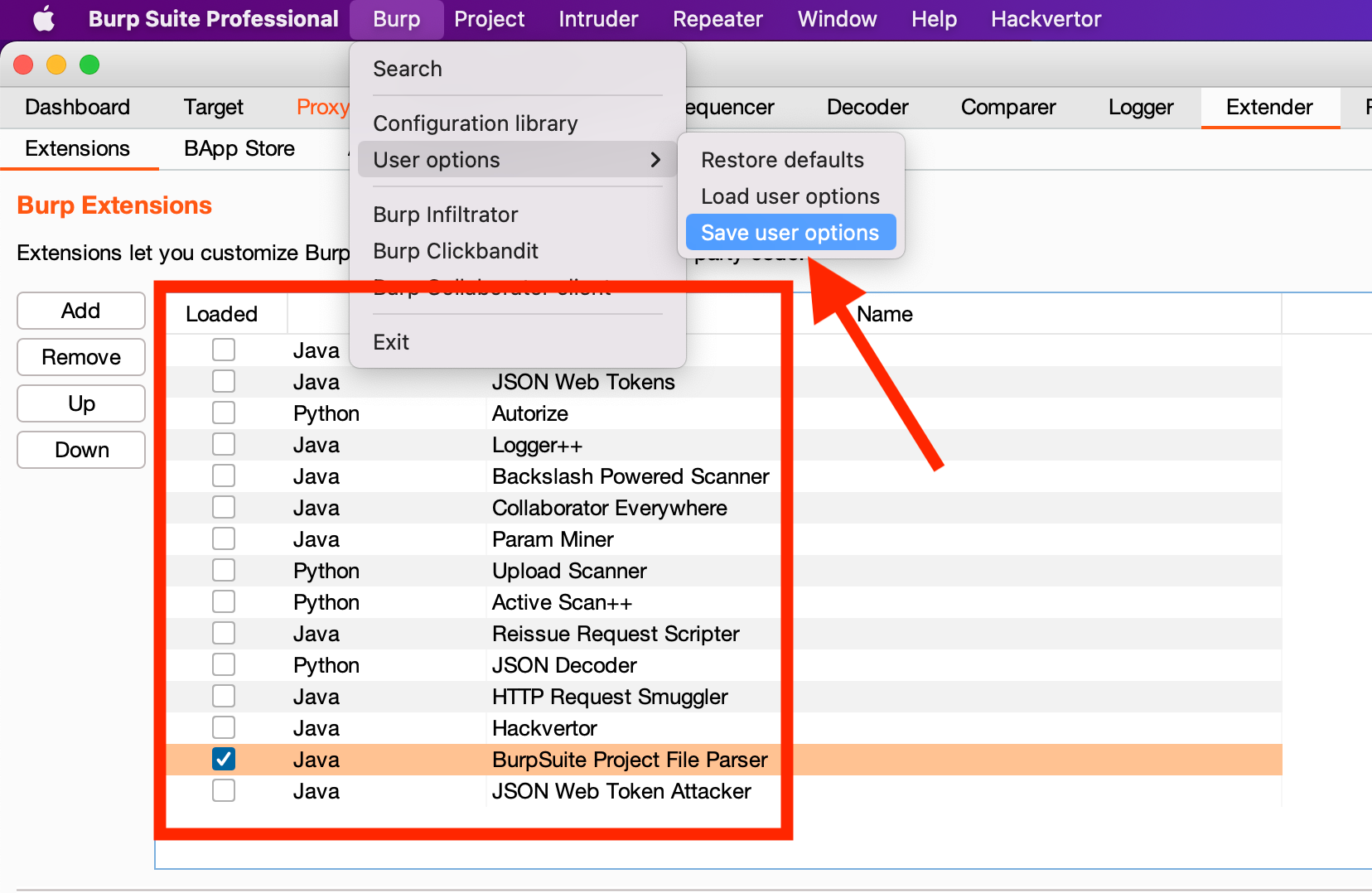
Next, disable all other Extensions except "BurpSuite Project File Parser" and "Save user options" as a new file (i.e. "ONLY_BURP_PROJECT_PARSER.json"):
Finally, before closing Burp Suite, click "Load user options" and load your original custom options (i.e. "DEFAULT_BURP_USER_OPTIONS.json") back in. This way, the next time you open Burp Suite GUI your configuration will be the same as what you are used to.
Testing
It's time to test our setup. Run the following command against an existing project file to verify everything is working correctly. Make sure to replace 2022-06-08.burp with the name of your Burp Suite Project file and the location of your burpsuite jar file (e.g. ~/Downloads/burpsuite_pro_v2022.3.6.jar below):
java -jar -Djava.awt.headless=true \
-Xmx2G \
--add-opens=java.desktop/javax.swing=ALL-UNNAMED \
--add-opens=java.base/java.lang=ALL-UNNAMED \
~/Downloads/burpsuite_pro_v2022.3.6.jar \
--user-config-file=ONLY_BURP_PROJECT_PARSER.json \
--project-file=2022-06-08.burp \
auditItems
You should see audit items in the result:
Warning: the fonts "Times" and "Times" are not available for the Java logical font "Serif", which may have unexpected appearance or behavior. Re-enable the "Times" font to remove this warning.
{"Message":"Loaded project file parser; updated for burp 2022."}
[auditItems]
{"issueName":"Unencrypted communications","url":"http://site1:80/","confidence":"Certain","severity":"Low"}
{"issueName":"Unencrypted communications","url":"http://site2:80/","confidence":"Certain","severity":"Low"}
...
Maybe not light speed but it's waayyy faster.
burpsuite-project-parser Flags
At this point we now have a speedier way to parse project files. Before giving a few examples let's reiterate what flags are available as of burpsuite-project-parser 1.0. Remember any output will be in JSON:
auditItems: Outputs the audit findings from a project file.
siteMap: Outputs all requests/responses from the site map.
proxyHistory: Outputs all requests/responses from the site map.
responseHeader=[regex]: Using the [regex] output any response that matches in the response headers.
responseBody=[regex]: Using the [regex] output any response that matches in the response body.
storeData=[MongoDB Host]: Store all requests/responses to a MongoDB server; check out the Github project for the required MongoDB settings.
Feeding Data into the Pipeline
Before we finish up let's do a few examples.
Here is a bash one-liner to output all of the findings from all of the project files in the current directory:
Linux:
find . -maxdepth 1 -name "*.burp" | xargs -i{} \
java -jar -Djava.awt.headless=true \
-Xmx2G \
--add-opens=java.desktop/javax.swing=ALL-UNNAMED \
--add-opens=java.base/java.lang=ALL-UNNAMED \
~/Downloads/burpsuite_pro_v2022.3.6.jar \
--user-config-file=ONLY_BURP_PROJECT_PARSER.json \
--project-file={} \
auditItems 2>/dev/null
OS X:
find . -maxdepth 1 -name "*.burp" | xargs -I{} \
java -jar -Djava.awt.headless=true \
-Xmx2G \
--add-opens=java.desktop/javax.swing=ALL-UNNAMED \
--add-opens=java.base/java.lang=ALL-UNNAMED \
~/Downloads/burpsuite_pro_v2022.3.6.jar \
--user-config-file=ONLY_BURP_PROJECT_PARSER.json \
--project-file={} \
auditItems 2>/dev/null
Search every project file for Servlet or nginx in response header:
find . -maxdepth 1 -name "*.burp" | xargs -I{} \
java -jar -Djava.awt.headless=true \
-Xmx2G \
--add-opens=java.desktop/javax.swing=ALL-UNNAMED \
--add-opens=java.base/java.lang=ALL-UNNAMED \
~/Downloads/burpsuite_pro_v2022.3.6.jar \
--user-config-file=ONLY_BURP_PROJECT_PARSER.json \
--project-file={} \
responseHeader='.*(Servlet|nginx).*' 2>/dev/null
Grep all proxyHistory of all project files for "graphql" anywhere and output the URL where it was seen:
find . -maxdepth 1 -name "*.burp" | xargs -I{} \
java -jar -Djava.awt.headless=true \
-Xmx2G \
--add-opens=java.desktop/javax.swing=ALL-UNNAMED \
--add-opens=java.base/java.lang=ALL-UNNAMED \
~/Downloads/burpsuite_pro_v2022.3.6.jar \
--user-config-file=ONLY_BURP_PROJECT_PARSER.json \
--project-file={} \
proxyHistory 2>/dev/null \
| grep -Fi "graphql" \
| jq -c '{"url":.request.url}' | cut -d\" -f4
Grep for "url=" from proxyHistory in the url and uri only:
find . -maxdepth 1 -name "*.burp" | xargs -I{} \
java -jar -Djava.awt.headless=true \
-Xmx2G \
--add-opens=java.desktop/javax.swing=ALL-UNNAMED \
--add-opens=java.base/java.lang=ALL-UNNAMED \
~/Downloads/burpsuite_pro_v2022.3.6.jar \
--user-config-file=ONLY_BURP_PROJECT_PARSER.json \
--project-file={} \
proxyHistory 2>/dev/null \
| grep -F "{" \
| jq -c '{"url":.request.url,"uri":.request.uri}' \
| cut -d\" -f4,8 | tr -d \" \
| grep -iF "url="
YMMV
Please keep in mind this plug-in follows a design philosophy of "one tool for the job". Grepping through the proxyHistory and only outputting a URL may not be the most accurate way to get the data you are looking for. Instead, maybe putting everything into MongoDB (ElasticSearch, etc) or a custom JSON search script works better. In this next post we will take this idea further.
Please submit bugs and improvements to the Github project if you want!
